How To Export Apple Podcasts to mp3 Files
May 2, 2020 · 4 minute read · CommentsOr how to export podcasts to your Sandisk Clip or other non-Apple device.
2022 Update: I have made a standalone app that offers more features and works on more computers. Find the app and installation instructions on github.
Apple Podcasts, introduced in macOS Catalina, is a convenient app: every podcast page I’ve ever visited includes a “Listen on Apple Podcasts” link, it’s already installed on my computer, and I can download episodes for offline listening. The problem is that I can’t get those offline files out of Apple Podcasts, to transfer them to my small waterproof mp3 player.
To solve this problem, I made a small app that finds all downloaded episodes, then allows you to select and copy a selection to a directory of your choice. Download and install the app here. You will need to authorize the app in Security & Privacy - full instructions here.
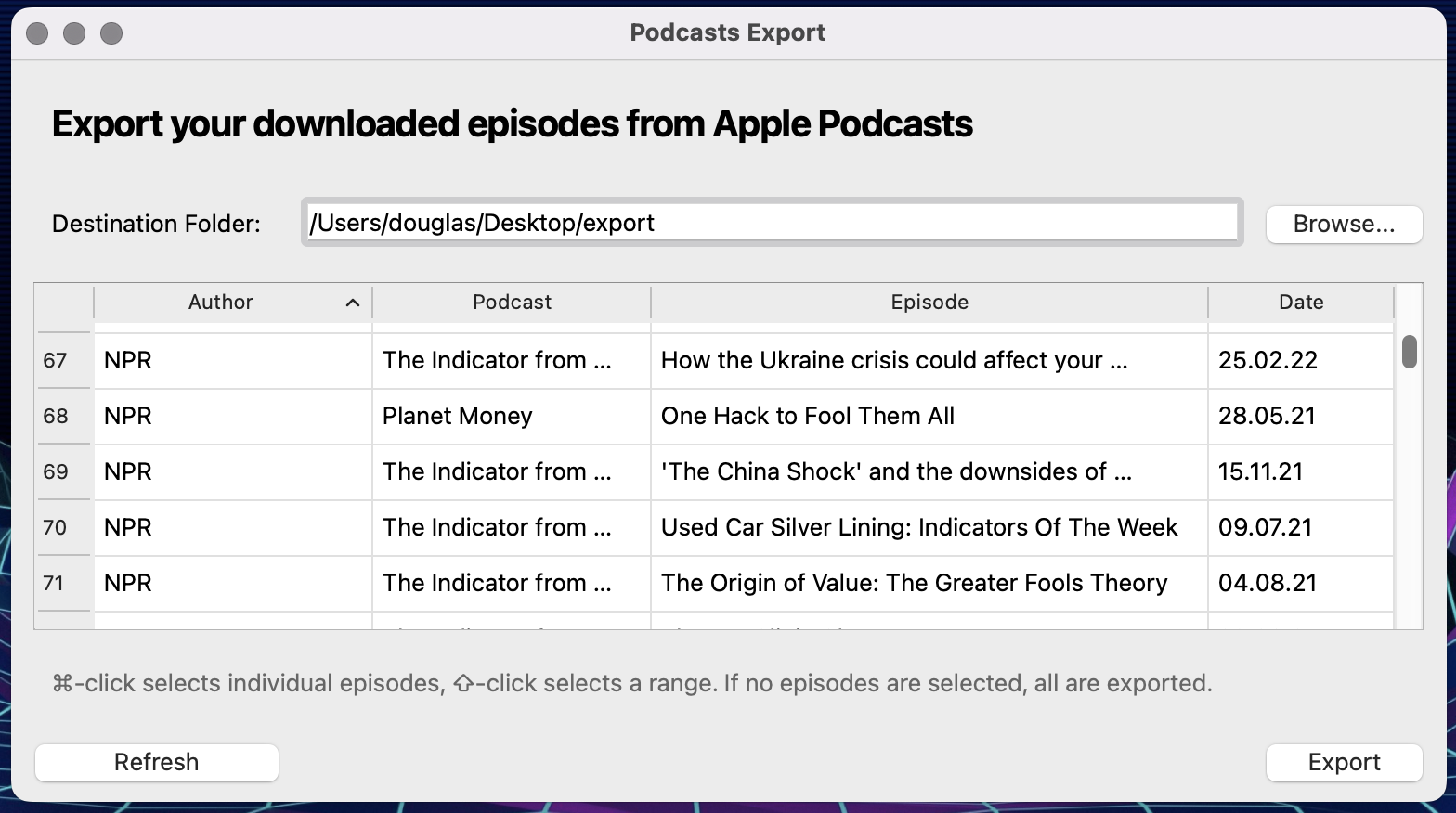
This version should work on more computers than the previous version (the Automator service), because it is packaged as a regular macOS app. Issues related to missing libraries should be fixed.
2020 Version: Automator service
Initially, I made a quick Automator service that copies all downloaded episodes. Download it here, unzip the file, and open the .workflow file. MacOS should offer to install it: Do you want to install the “Export Downloaded Podcasts” quick action? Once installed, you’ll have a new service available in Podcasts:
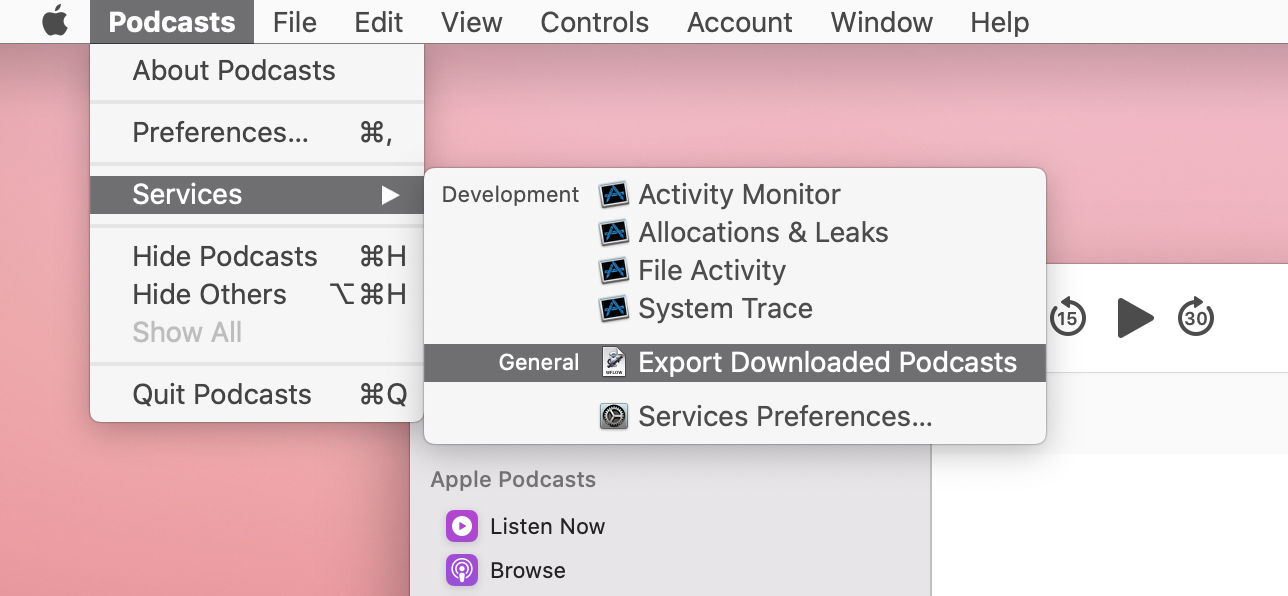
Clicking this will prompt you to choose a destination folder (on your desktop for example). It will then copy all downloaded episodes to this folder, tagging them in the process so that your music player indexes them correctly. The first time you run this service, it may ask for your password. It is needed to install a Python library to manage mp3 file tags.
You can now copy these files to any device. Happy listening!
Side notes
For cautious readers, the password is prompted by this line in a script:
osascript -e 'do shell script "/usr/bin/pip3 install mutagen" with administrator privileges'
It executes the shell command pip3 install mutagen. My script never sees the password.
How does it work?
Podcasts stores its data in the ~/Library/Group Containers/243LU875E5.groups.com.apple.podcasts directory, structured like so:
.
├── Documents
│ ├── MTLibrary.sqlite
│ ├── ...
├── Library
│ ├── Cache
│ │ ├── 07AED83C-4AA9-4EAC-9589-16BFADD32D31.mp3
│ │ ├── 79B12784-8123-4CC1-B2B5-860636224A12.mp3
│ │ ├── 92C57A6D-94DC-4B3E-9BB4-A1B2041B5F09.mp3
│ │ ├── FF865F4C-55BC-408A-A10A-45EBBE32BF67.mp3
... ... ...
As far as I can tell, the path is the same on everyone’s computer. The Library/Cache subfolder contains an mp3 file for each downloaded episode, named after an internal unique id and with empty ID3 tags. Since the tags are empty, we need to look elsewhere to identify these files. We find that Documents contains a sqlite database that stores the application’s Core Data, including lists of podcasts and episodes.
It was actually easiest to use the database as a starting point. The first step was to find all episodes that are cached and find their associated podcast name and author:
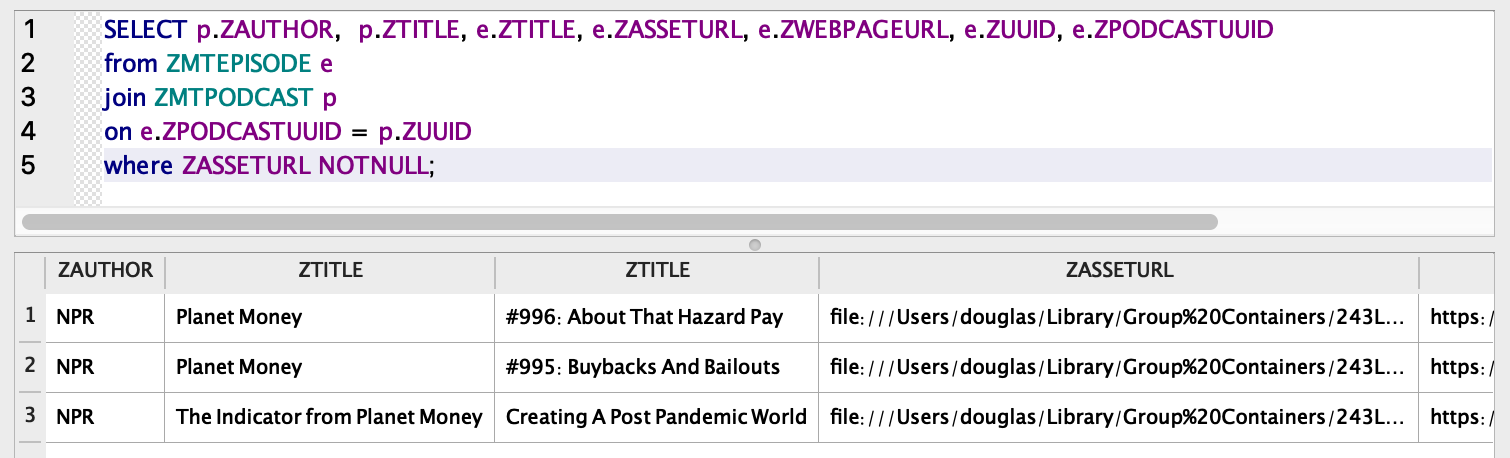
Quick shout-out to DB browser for SQLite that made this exploration quite easy.
Once we’ve figured out the SQL query, we just need to execute it in a Python script and loop through each result, copying the file from ZASSETURL to the destination folder and setting the ID3 tags.
For convenience, I wrapped this python script in an Automator workflow that registers as a service for the Podcasts App. You can see the full code here: https://github.com/douglas-watson/podcasts_export.
Update from 4 May 2020
The first version of this workflow was written in Python 2.7, for easier integration in Automator. The ID3 tagging libraries I could install with the system’s easy_install did not support unicode, so I switched to Python 3 and the mutagen library. Executing python3 in Automator requires wrapping the code into a bash script, so this is now a python script, wrapped in a bash script, wrapped in an Automator workflow.